
티스토리 뷰
[ML Andrew Ng] C2-Advanced Learning Algorithms 강의 (W1-1) Neural Netowork Intuition
Life4AI 2024. 9. 11. 11:29
Neural Network Intuition - Neurons and the brain
신경망(neural network), 특히 인공 신경망(artificial neural network)은 인간의 뇌가 학습하고 사고하는 방식을 모방하려는 동기에서 처음 개발되었다. 비록 오늘날의 신경망은 실제 뇌의 작동 방식과 크게 다르지만, 초기 목표는 생물학적 뉴런의 기능을 소프트웨어로 구현하는 것이었다.

신경망 연구는 1950년대에 시작되었지만, 한동안 관심을 받지 못하다가 1980~1990년대 초에 다시 주목받았다. 특히 손글씨 숫자 인식 등 일부 분야에서 성과를 내면서, 우편번호를 읽거나 수표의 금액을 인식하는 데 사용되기도 했다.
그러나 1990년대 후반에는 다시 인기를 잃었다. 그러다 2005년경 다시 부상하기 시작하면서 '딥러닝'이라는 새로운 이름으로 재브랜딩되었고, 이후 다양한 응용 분야에서 혁신을 일으켰다.
현대 신경망 또는 딥러닝이 가장 먼저 큰 영향을 미친 분야는 음성 인식이다. 이후 컴퓨터 비전, 텍스트 처리, 자연어 처리 등으로 확장되었고, 현재는 기후 변화, 의료 영상 분석, 온라인 광고, 제품 추천까지 다양한 영역에서 사용되고 있다.
그렇다면 실제로 뇌는 어떻게 작동할까?

뇌의 뉴런은 전기적 자극을 통해 다른 뉴런과 연결되고 신호를 주고받는다.
인공 신경망은 이 생물학적 뉴런의 기능을 매우 단순화한 수학적 모델을 사용한다. 인공 뉴런은 입력값을 받아 계산을 한 후, 출력값을 내보내는 역할을 한다. 여러 인공 뉴런을 동시에 시뮬레이션하여 복잡한 패턴을 학습하는 것이 신경망의 핵심이다.
그렇다면 왜 신경망은 최근 몇 년 동안 급격히 발전한 것일까?

그 이유는 주로 데이터 양의 증가와 컴퓨팅 성능의 향상에 있다.
데이터 양이 폭발적으로 증가하면서, 기존의 선형 회귀나 로지스틱 회귀 같은 알고리즘은 더 많은 데이터를 활용하는 데 한계를 보였다. 반면, 신경망은 큰 데이터셋을 활용할수록 성능이 향상될 수 있었다.
특히, 작은 신경망은 성능이 제한적일 수 있지만, 중형 또는 대형 신경망으로 확장하면 성능이 지속적으로 개선되는 경향이 있다. 이는 대용량 데이터를 효과적으로 활용할 수 있는 신경망의 능력 덕분이다. 이러한 성능 향상은 음성 인식, 이미지 인식, 자연어 처리 등 다양한 응용 분야에서 가능하게 했다.
이러한 딥러닝의 부흥은 GPU의 발전과도 밀접한 관련이 있다. GPU는 원래 고성능 그래픽을 처리하기 위해 설계되었지만, 딥러닝 연산에도 매우 유리한 것으로 나타났다. 이처럼 컴퓨팅 성능의 향상과 더불어 딥러닝 알고리즘의 발전이 신경망 기술을 오늘날의 수준으로 끌어올렸다.
결론적으로, 신경망은 초기에는 뇌를 모방하려는 시도로 시작되었지만, 이후 데이터와 컴퓨팅 기술의 발전 덕분에 다양한 응용 분야에서 빠르게 발전할 수 있었다.
Neural Network Intuition - Demand Prediction
신경망의 작동 방식을 설명하기 위한 간단한 예제를 보겠다.
이번 예제에서는 수요 예측을 통해 특정 제품이 베스트셀러가 될지 예측하는 방법을 설명하겠다.
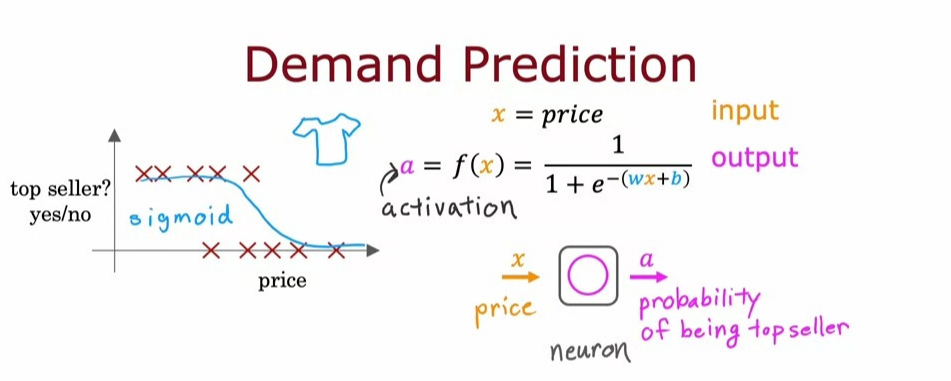
먼저, 다양한 가격대로 판매된 여러 티셔츠의 데이터를 수집했다고 가정해보자. 이 데이터에서 입력 값 \(x\)는 티셔츠의 가격이다. 로지스틱 회귀를 적용하여 데이터를 시그모이드 함수에 피팅하면 티셔츠가 베스트셀러가 될 확률이 나온다.
이전까지는 우리 학습 알고리즘의 출력을 \(f(x)\)로 표현했지만, 신경망의 맥락에서는 이 출력값을 \(a\)라고 표현한다. 여기서, \(a\)는 '활성화(activation)'을 의미하며, 활성화는 뉴런이 다른 뉴런으로 신호를 얼마나 많이 보내고 있는 지를 나타낸다.
이 로지스틱 회귀 모델은 단순화된 뉴런의 역할을 한다.
뉴런은 가격 \(x\)를 입력으로 받아 공식에 따라 계산을 수행한 후, 베스트셀러가 될 확률인 활성화 값 \(a\)를 출력한다.
뉴런을 이해하는 또 다른 방법은, 하나 이상의 입력(예: 티셔츠 가격)을 받아, 하나 이상의 출력을 내는 작은 컴퓨터로 보는 것이다. 물론 실제 뇌에서 뉴런이 처리하는 방식은 훨씬 더 복잡하다. 로지스틱 회귀 알고리즘은 생물학적 뉴런이 작동하는 방식의 매우 단순화된 버전일 뿐이다. 그럼에도 불구하고, 딥러닝 알고리즘은 이러한 단순화된 구조를 기반으로 매우 효과적으로 작동하고 있다. 이처럼 인공 신경망은 인간 뇌의 뉴런을 모방한 매우 단순한 모델이지만, 딥러닝 알고리즘은 다양한 응용 분야에서 놀라운 성과를 보여주고 있다.
단일 뉴런을 이해했다면, 이제 여러 뉴런을 연결하여 신경망을 구축할 수 있다.
좀 더 복잡한 수요 예측 예제로, 티셔츠가 베스트셀러가 될지를 예측하는 네 가지 특징(price, shipping cost, marketing, material)을 고려해보겠다.

티셔츠가 베스트셀러가 될지 여부는 다양한 요인에 따라 결정될 수 있다.
1. 경제성(affordability): 이 티셔츠가 얼마나 저렴한가?
2. 인지도(awareness): 사람들이 이 티셔츠를 얼마나 알고 있는가?
3. 품질에 대한 인식(perceived quality): 사람들이 이 티셔츠를 고품질로 인식하는가?
이제 이러한 요소들을 기반으로 신경망을 설계해보겠다.
- 첫 번째 뉴런 - 경제성 예측
티셔츠가 얼마나 저렴하다고 인식될지는 가격과 배송비의 함수일 수 있다. 이 뉴런은 가격과 배송비를 입력받아, 사람들이 이 티셔츠를 경제적이라고 생각할 확률을 계산한다. 여기서 우리는 로지스틱 회귀 단위를 사용해 이 확률을 추정할 수 있다.
- 두 번째 뉴런 - 인지도 예측
사람들이 이 티셔츠를 알고 있는 정도는 주로 마케팅에 의해 결정된다. 따라서 이 뉴런은 마케팅 데이터를 입력으로 받아, 사람들이 이 티셔츠에 대해 얼마나 알고 있을지를 예측한다.
- 세 번째 뉴런 - 품질에 대한 인식 예측
사람들은 가격과 소재 품질을 보고 티셔츠의 품질을 판단할 수 있다. 이 뉴런은 가격과 소재 품질을 입력받아 사람들이 이 티셔츠를 고품질로 인식할 가능성을 계산한다.
> 이 세 가지 뉴런(경제성, 인지도, 품질에 대한 인식)의 출력 값을 모두 받아, 이를 최종 뉴런에 연결합니다. 이 최종 뉴런은 다시 로지스틱 회귀 단위로, 세 가지 입력값을 기반으로 티셔츠가 베스트셀러가 될 확률을 예측한다.
신경망의 기본 개념을 설명하기 위해, 먼저 뉴런들을 어떻게 그룹화하고 연결하는지를 살펴보겠다.

여러 뉴런을 하나의 레이어(layer)로 묶을 수 있으며, 각 레이어는 유사한 특징을 입력받아 숫자 몇 개를 출력한다. 예를 들어, 경제성, 인지도, 품질 인식을 예측하는 세 개의 뉴런은 하나의 레이어를 형성한다. 이 최종 뉴런은 출력 레이어(output layer)라고 불리며, 입력 값들을 묶어 입력 레이어(input layer)라고 부른다.
신경망에는 입력 레이어와 출력 레이어 외에도 히든 레이어(은닉층, hidden layer)가 존재한다. 히든 레이어는 중간 계산을 담당하며, 이 층에서 계산된 값들은 훈련 데이터에서는 직접 관찰할 수 없다. 예를 들어, 경제성이나 인지도 같은 값은 데이터셋에서 주어지지 않으며, 따라서 이 값을 "숨겨져 있다"고 표현한다. 그래서 중간에 있는 레이어를 히든 레이어라고 부르는 것이다.
그리고 신경망 용어로, 경제성, 인지도, 인지된 품질을 예측하는 값을 활성화(activation)라고 부른다. 이 용어는 생물학적 뉴런에서 유래한 것으로, 뉴런이 다른 뉴런에게 얼마나 많은 신호를 보내는지를 나타낸다. 경제성, 인지도, 품질 인식에 대한 예측값은 세 뉴런의 활성화 값이며, 최종 출력 뉴런의 값도 활성화의 일종이다.
신경망의 계산 과정을 보면, 가격, 배송비, 마케팅 데이터, 소재 품질과 같은 네 가지 특징이 입력된다. 이 네 개의 값은 입력 계층을 통해 들어가고, 첫 번째 레이어의 뉴런들이 각각 활성화 값을 계산한다. 이 활성화 값들은 다시 출력 레이어에 전달되어 최종 예측 값, 즉 티셔츠가 베스트셀러가 될 확률을 출력한다.
이제 신경망을 좀 더 단순화해 보겠다.
지금까지는 뉴런을 하나씩 살펴보고 각 뉴런이 어떤 입력을 받을지를 수동으로 결정해야 했습. 예를 들어, 경제성은 가격과 배송비의 함수로 입력되었고, 인지도는 마케팅과 관련된 입력으로 처리되었다. 하지만, 큰 규모의 신경망을 구축할 때, 각 뉴런이 어떤 입력을 받을지 일일이 지정하는 것은 매우 번거로운 작업이 될 수 있다.

실제로 신경망이 구현되는 방식은 훨씬 더 단순하다. 중간 계층에 있는 모든 뉴런은 이전 계층의 모든 입력 값에 접근할 수 있다. 다시 말해, 각 뉴런은 입력 계층의 모든 특징을 고려할 수 있는 능력을 가진다. 이를 통해 신경망은 더 효율적으로 계산을 수행하게 되며, 필요한 경우 특정 기능에만 집중하도록 자동으로 학습할 수 있다. (매개변수를 적절하게 설정하여, 경제성과 가장 관련있는 일부 기능에만 집중하는 방법 등)
따라서, 신경망의 중요한 특성 중 하나는, 경제성, 인지도, 품질 인식 등과 같은 특징을 사람이 명시적으로 설정할 필요가 없다는 것이다. 신경망은 데이터로부터 훈련을 통해 이러한 숨겨진 특징들을 스스로 학습해낸다. 즉, 은닉 계층에서 사용할 적절한 기능들을 신경망이 알아서 결정하는 것이죠. 이러한 특성 덕분에 신경망은 매우 강력한 학습 알고리즘이 될 수 있다.
앞서 봤던 주택 가격 예측 예시를 생각해보자.
부지의 너비와 깊이를 곱하여 부지의 크기라는 새로운 특성을 만들어서, 기존의 입력 값만으로는 해결하기 어려운 문제를 쉽게 풀 수 있도록 하였다.

신경망도 유사한 방식으로 동작하지만, 차이점은 신경망이 적절한 특성을 자동으로 학습해낸다는 것이다.
신경망의 다른 몇 가지 예를 살펴보겠다.
이번에는 두 개 이상의 은닉 계층이 있는 예제이다.

티셔츠의 가격, 배송비, 마케팅 노력 등 여러 특징들이 입력 벡터 \(X\)로 전달된다. 입력 벡터 \(X\)는 첫 번째 은닉 계층에 전달되어 은닉 계층의 뉴런들이 입력을 처리하고, 각 뉴런에서 계산된 값들이 활성화 값으로 출력한다. 만약 이 계층에 뉴런이 세 개 있다면, 세 개의 활성화 값이 출력한다.
첫 번째 은닉 계층의 출력이 두 번째 은닉 계층으로 전달한다. 이 계층은 첫 번째 은닉 계층의 활성화 값을 기반으로 추가적인 계산을 수행하며, 활성화 값이 다시 출력한다. 두 번째 은닉 계층의 뉴런이 두 개라면 두 개의 활성화 값이 출력한다. 두 번째 은닉 계층에서 나온 활성화 값이 출력 계층으로 전달되어 최종 예측값이 계산된다. 출력값은 신경망이 예측한 결과이다.
** 신경망 설계 시 고려사항
신경망을 설계할 때는 은닉 계층의 수와 각 계층의 뉴런 수를 결정해야 한다. 이는 신경망의 아키텍처를 결정하는 중요한 요소이다.
- 은닉 계층의 수: 은닉 계층이 많을수록 더 복잡한 패턴을 학습할 수 있지만, 학습 시간이 길어지고 과적합(overfitting)의 위험이 커질 수 있다.
- 각 은닉 계층의 뉴런 수: 각 계층의 뉴런 수가 많을수록 더 많은 정보를 처리할 수 있지만, 너무 많으면 계산 비용이 증가하고 최적화가 어려워질 수 있다.
** 다층 퍼셉트론이란?
이런 두 개 이상의 은닉 계층을 갖고 있는 신경망을 우린 다층 퍼셉트론(Multilayer Perceptron, MLP)이라 한다. MLP는 입력 계층, 은닉 계층, 출력 계층을 포함하며, 각 계층에서 뉴런들이 상호 연결되어 데이터를 전달하면서 점차 더 복잡한 패턴을 학습하게 된다.
Neural Network Intuition - Example: Recognizing Images
수요 예측 예제에서 신경망이 어떻게 작동하는지 살펴보았다.
이번에는 컴퓨터 비전 애플리케이션에서 신경망이 어떻게 작동하는 지 이해하기 위해, 이미지 데이터를 처리하고 특징을 추출하는 과정을 살펴보자.

얼굴 인식 애플리케이션은 입력으로 이미지를 받아, 이를 여러 은닉 계층을 통해 처리한 뒤 최종적으로 특정 인물의 신원을 예측하는 출력값을 생성한다. 이 이미지는 1,000x1,000 픽셀 크기이며, 각 픽셀은 0에서 255사이의 값으로 밝기나 색 농도를 나타낸다. (예: 197은 이미지의 맨 왼쪽 상단에 있는 픽셀의 밝기)
이 값을 통해 이미지가 그려지는데, 컴퓨터는 이를 행렬로 표현한다. (1,000x1,000 행렬로 나타낼 수 있음)
이미지를 신경망에 입력하기 위해, 이 2차원 행렬을 1차원 벡터로 변환한다. 그럼, 1,000 x 1,000 픽셀의 행렬을 1차원으로 펼치면 1백만 개의 숫자를 포함하는 백만 차원의 벡터가 생성된다.
얼굴 인식 문제는 백만 픽셀 밝기 값을 갖는 특징 벡터를 입력으로 받아 사진 속 인물의 신원을 출력하는 신경망을 훈련시킬 수 있느냐는 것입니다.
이 작업을 수행하기 위한 신경망을 구축하는 방법은 다음과 같다.

입력 벡터 \(X\)는 첫 번째 은닉 레이어로 전달되어고, 이 첫 번째 은닉 계층의 출력값(활성화 값)은 두 번째 은닉 계층에 공급되고 이 출력은 세 번째 계층에 공급되고 마지막으로 출력 계층에 공급됩니다. 그러면 출력 계층은 이 사람이 특정인일 확률을 추정한다.
신경망이 컴퓨터 비전에서 어떻게 학습하고 이미지를 처리하는지 시각적으로 분석해보자.

- 첫 번째 은닉 계층: 입력 벡터(백만 개의 픽셀 값)를 받아 이미지의 저수준 특징(엣지, 패턴)을 추출한다. 이 은닉 계층은 뉴런들의 활성화 값으로 이미지의 중요한 정보를 요약한다.
- 두 번째 은닉 계층: 첫 번째 은닉 계층의 출력값을 받아 더 고차원적인 특징(눈, 코, 입의 형태)을 학습한다.
- 세 번째 은닉 계층: 두 번째 은닉 계층의 출력값을 받아 얼굴 전반의 윤곽이나 사람의 특정 특징을 학습한다.
- 출력 계층: 마지막 출력 계층은 최종적으로 사람의 신원을 예측한다. 예를 들어, 이 출력은 특정인에 대한 확률 값으로 나타날 수 있습니다. 출력값이 0.9라면, 해당 인물이 특정인일 확률이 90%라는 의미이다.
신경망의 각 계층은 이미지에서 점점 더 복잡한 특징을 추출해나가며 모델을 학습한다.
다시 말해, 신경망의 각 계층은 다른 크기의 시각적 창을 통해 이미지를 본다고 생각할 수도 있다. 첫 번째 레이어에서는 작은 영역만을 보고 작은 선이나 가장자리를 감지하지만, 두 번째와 세 번째 레이어로 갈수록 점점 더 큰 영역을 보며 더 복잡한 구조를 인식하게 된다.
여기서 신경망의 가장 놀라운 점 중 하나는, 사람이 개입하지 않고도 데이터만으로 이 모든 특징을 스스로 학습할 수 있다는 점이다. 우리는 첫 번째 레이어가 짧은 선을 찾고, 두 번째 레이어가 눈과 코를 찾고, 세 번째 레이어가 얼굴 전체를 찾도록 일일이 지시하지 않는다. 데이터만으로 신경망은 이러한 특징들을 자동으로 감지하고 학습한다.
이와 같은 신경망의 학습 방식은 다양한 유형의 데이터에 적용될 수 있다.

자동차 이미지 데이터로 신경망을 훈련시키면 신경망은 비슷한 방식으로, 첫 번째 계층에서는 자동차의 기본적인 선이나 가장자리를 감지하고, 두 번째 계층에서는 자동차의 부품을 인식하며, 마지막 세 번째 계층에서는 전체 자동차 형태를 학습한다.
결과적으로, 신경망은 다양한 종류의 데이터를 입력받아 여러 은닉 계층을 거치며 점점 더 복잡한 특징을 학습하고, 이를 통해 정확한 예측을 할 수 있게 된다. 데이터만으로 특징을 자동으로 학습할 수 있다는 점은 신경망이 가진 큰 강점이며, 이는 컴퓨터 비전 분야에서 특히 유용하게 활용된다.
Practice quiz - Neural networks intuition

'Coursera 강의 > Machine learning Specialization' 카테고리의 다른 글
- Total
- Today
- Yesterday
- action value function
- 숏코딩
- 비용함수
- 11870
- 파이썬
- numpy 배열 속성
- **
- NumPy
- **kwargs
- 딥러닝
- 로지스틱 회귀
- omp: error #15
- python
- state value function
- Sort
- Andrew Ng
- 앤드류응
- computation graph
- *
- policy function
- 강화학습
- baekjoon
- *args
- 강의노트 정리
- 경사하강법
- 백준
- 손실함수
- sorted
- numpy 배열 생성
- adrew ng 머신러닝 강의
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |