
티스토리 뷰
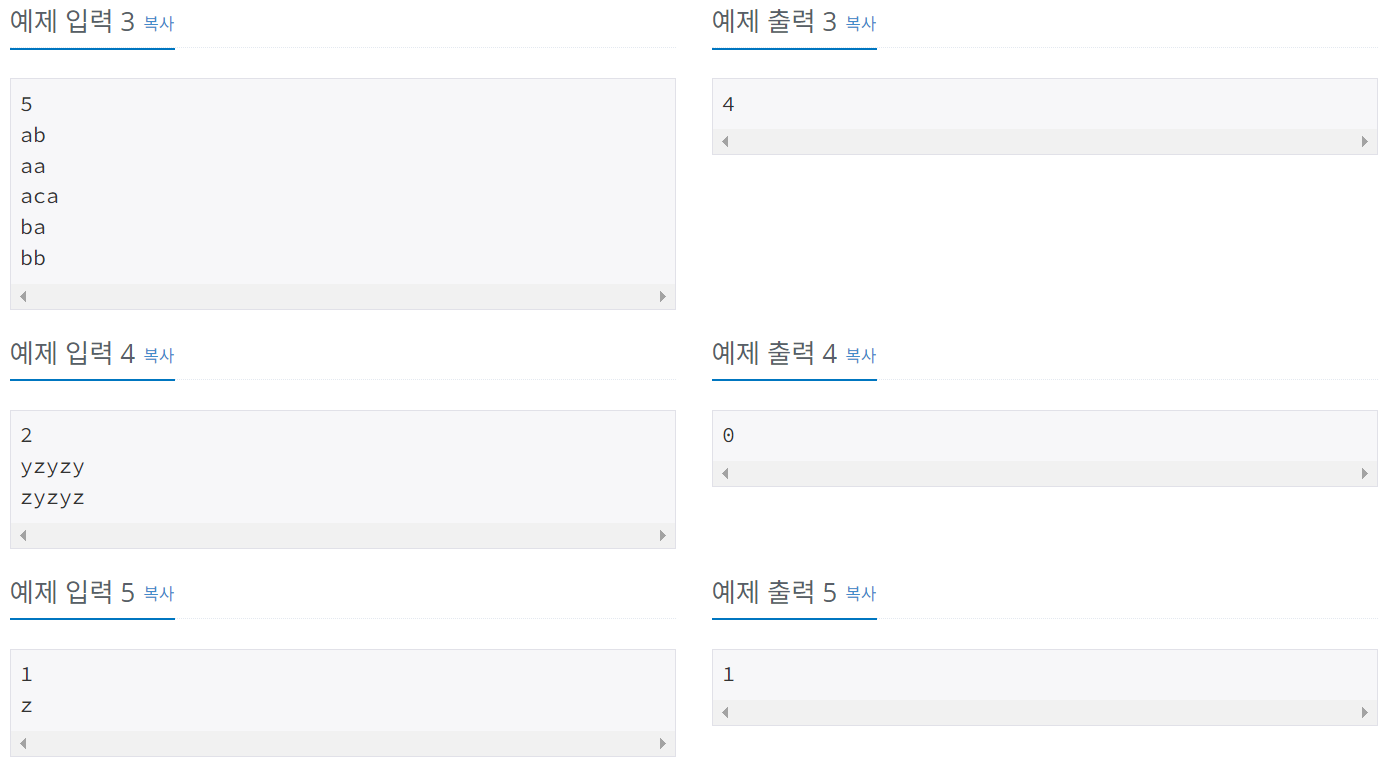
문제
: 그룹 단어란 단어에 존재하는 모든 문자에 대해서, 각 문자가 연속해서 나타나는 경우만을 말한다. 예를 들면, ccazzzzbb는 c, a, z, b가 모두 연속해서 나타나고, kin도 k, i, n이 연속해서 나타나기 때문에 그룹 단어이지만, aabbbccb는 b가 떨어져서 나타나기 때문에 그룹 단어가 아니다.
단어 N개를 입력으로 받아 그룹 단어의 개수를 출력하는 프로그램을 작성하시오.
입출력 규칙
1. 입력첫째 줄에 단어의 개수 N이 들어온다. N은 100보다 작거나 같은 자연수이다. 둘째 줄부터 N개의 줄에 단어가 들어온다. 단어는 알파벳 소문자로만 되어있고 중복되지 않으며, 길이는 최대 100이다.
2. 출력
첫째 줄에 그룹 단어의 개수를 출력한다.


문제 풀이
<내 풀이1>
tmp 라는 리스트를 만들어서, 이전에 등장한 문자를 기록한다.
- 이전에 등장하지 않은 문자라면, 추가해준다.
- 이전에 등장했다면, 이제 연속적인지 아니면 그전에 등장했는지 확인해야한다. 이건 tmp[-1]을 확인하면 된다. 연속되는 문자라면 tmp[-1]이 지금 문자와 같을 것이고, 그렇지 않으면 다를 것이다.
- 연속되지 않고, 그 이전에 나온 문자가 있다면, cnt에서 1을 감소시키고, 해당 단어에 대한 반복을 중단한다.
result = int(input())
for _ in range(result):
tmp = []
for s in input():
if s not in tmp:
tmp.append(s)
else:
if tmp[-1] != s:
result -= 1
break
print(result)
<내 풀이2>
단어의 출현 위치를 통해서 확인할 수 있다.
- word.find(word[i-1])는 이전 문자의 첫 번째 출현 위치를 찾는다.
- word.find(word[i])는 현재 문자의 첫 번째 출현 위치를 찾는다.
- 만약 이전 문자의 첫 번째 출현 위치가 현재 문자의 첫 번째 출현 위치보다 크다면, 이는 이전 문자가 현재 문자보다 나중에 처음 등장했다는 뜻이다.
- 이 경우 result를 1 감소시키고, 해당 단어에 대한 반복을 중단한다.
result = int(input())
for _ in range(result):
word = input()
for i in range(1, len(word)):
if word.find(word[i-1]) > word.find(word[i]):
result -= 1
break
print(result)
입력: "abc"
- a와 b 비교: find('a') == 0, find('b') == 1 (문제 없음)
- b와 c 비교: find('b') == 1, find('c') == 2 (문제 없음)
- 그룹 단어임
입력: "aba"
- a와 b 비교: find('a') == 0, find('b') == 1 (문제 없음)
- b와 a 비교: find('b') == 1, find('a') == 0 (문제 있음!)
- 그룹 단어 아님
<숏코딩>
sorted를 이용하였다. 진짜 이런 생각을 어떻게 할까?
print(sum([*x]==sorted(x,key=x.find)for x in open(0))-1)#pycharm
cnt = 0
for _ in range(int(input())):
x = input()
cnt += [*x]==sorted(x,key=x.find)
print(cnt)
- 각 단어에 대해 [ *x ] == sorted( x, key=x.find ) 조건을 사용하여 그룹 단어인지 판별한다.
- sorted(x, key=x.find) : 문자가 처음 등장하는 위치에 따라 정렬된 리스트를 만든다.
- 원래 리스트 [ *x ]와 정렬된 리스트가 동일하면 그룹 단어로 간주된다.
입력: "abcabc"
- [ *x ] = ['a', 'b', 'c', 'a', 'b', 'c']
- sorted(x, key=x.find) = ['a', 'a', 'b', 'b', 'c', 'c']
- [ *x ] == sorted( x, key=x.find ) 는 False(0)이다.
- 그룹 단어 아님
입력: "happy"
- [ *x ] = ['h', 'a', 'p', 'p', 'y']
- sorted(x, key=x.find) = ['h', 'a', 'p', 'p', 'y']
- [ *x ] == sorted( x, key=x.find ) 는 True(1)이다.
- 그룹 단어
'코딩 > 백준' 카테고리의 다른 글
| [백준/BOJ] 10798번: 세로읽기 (Python 파이썬) (0) | 2024.06.20 |
|---|---|
| [백준/BOJ] 2738번: 행렬 덧셈 (Python 파이썬) (0) | 2024.06.19 |
| [백준/BOJ] 2941번: 크로아티아 알파벳 (Python 파이썬) (1) | 2024.06.07 |
| [백준/BOJ] 1157번: 단어 공 (Python 파이썬) (0) | 2024.06.05 |
| [백준/BOJ] 10988번: 팰린드롬인지 확인하기 (Python 파이썬) (0) | 2024.06.05 |
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- adrew ng 머신러닝 강의
- 백준
- Andrew Ng
- 앤드류응
- 숏코딩
- computation graph
- omp: error #15
- 강화학습
- 비용함수
- python
- state value function
- Sort
- action value function
- policy function
- 강의노트 정리
- **kwargs
- 11870
- baekjoon
- 파이썬
- 손실함수
- 경사하강법
- sorted
- *
- **
- numpy 배열 속성
- numpy 배열 생성
- 딥러닝
- 로지스틱 회귀
- NumPy
- *args
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
글 보관함