
티스토리 뷰
문제
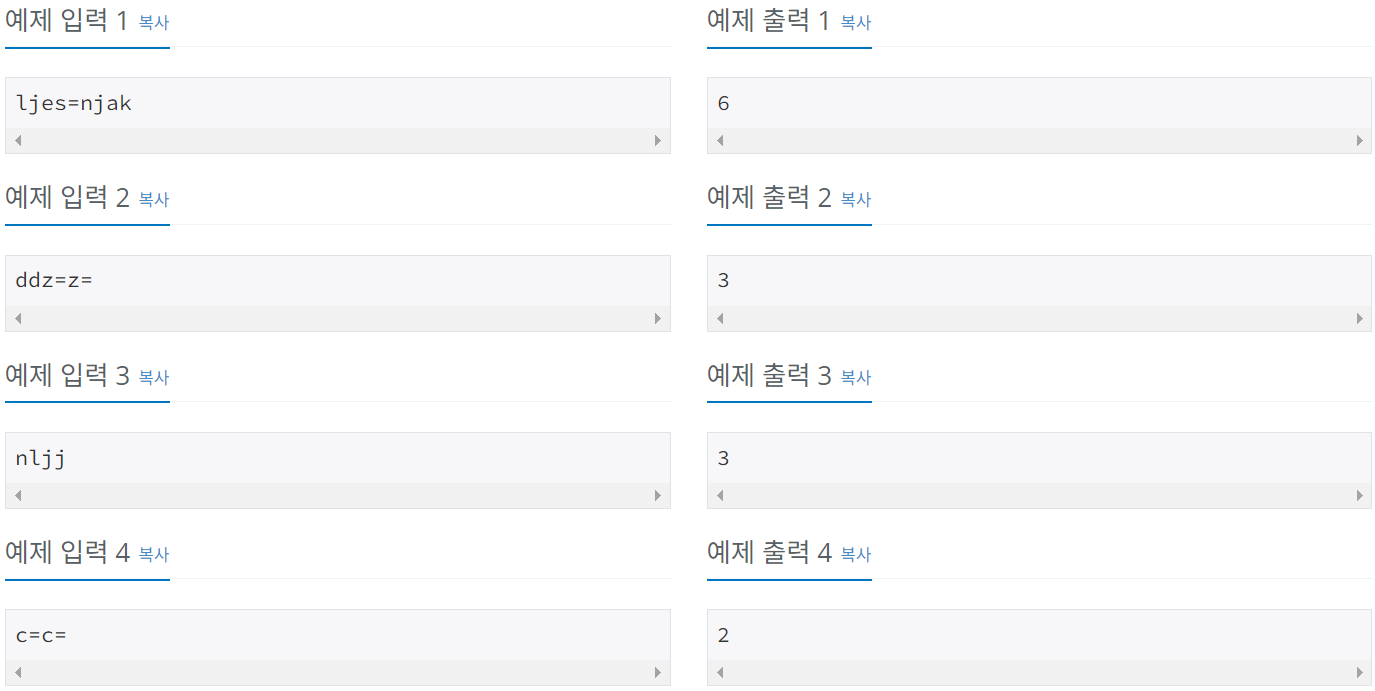
: 예전에는 운영체제에서 크로아티아 알파벳을 입력할 수가 없었다. 따라서, 다음과 같이 크로아티아 알파벳을 변경해서 입력했다.

예를 들어, ljes=njak은 크로아티아 알파벳 6개(lj, e, š, nj, a, k)로 이루어져 있다. 단어가 주어졌을 때, 몇 개의 크로아티아 알파벳으로 이루어져 있는지 출력한다.
dž는 무조건 하나의 알파벳으로 쓰이고, d와 ž가 분리된 것으로 보지 않는다. lj와 nj도 마찬가지이다. 위 목록에 없는 알파벳은 한 글자씩 센다.
입출력 규칙
1. 입력첫째 줄에 최대 100글자의 단어가 주어진다. 알파벳 소문자와 '-', '='로만 이루어져 있다.
단어는 크로아티아 알파벳으로 이루어져 있다. 문제 설명의 표에 나와있는 알파벳은 변경된 형태로 입력된다.
2. 출력
입력으로 주어진 단어가 몇 개의 크로아티아 알파벳으로 이루어져 있는지 출력한다.

문제 풀이
<내 풀이1>
크로아티아 알바펫을 하나의 문자로 바꿔서 문자열의 길이를 계산하려고 한다.
- replace() 함수를 이용하여서 '*'로 교체하였다.
- 그리고 나서 문자열 길이를 len()을 통해 계산하였다.
a = ['c=','c-','dz=', 'd-', 'lj', 'nj', 's=', 'z=']
word = input()
for s in a:
word = word.replace(s,'*')
print(len(word))
<숏코딩>
뭔가.. 새롭다.. 문자열 규칙을 잘 이용한거 같다...
import re
print(len(re.sub('dz=|[ln]j|\w\W','Z',input())))
정규식 패턴을 사용하였다.
- dz=: "dz="는 하나의 문자로 간주한다.
- [ln]j: "lj"와 "nj"도 각각 하나의 문자로 간주한다. 여기서, '[ln]'는 문자 l 또는 n 중 하나를 의미한다.
- \w\W: 모든 단어 문자가 뒤따르는 비단어 문자를 하나의 문자로 간주한다. 여기서, \w는 단어 문자를 의미하며, \W는 비단어 문자를 의미한다. \w\W는 단어 문자 뒤에 비단어 문자가 오는 경우를 매칭한다.
예를 들어, "a!"에서 a는 단어 문자이고 !는 비단어 문자이므로, 이 두 문자는 \w\W에 의해 매칭된다.
re 모듈 중 re.sub()를 통해 문자열에서 정규식 패턴과 매치되는 부분을 다른 문자열로 대체한다.
- re.sub('dz=|[ln]j|\w\W','Z',input()): 입력된 문자열에서 "dz=", "lj", "nj" 또는 다른 단어 문자와 비단어 문자 쌍을 찾아서 "Z"로 대체한다.
예시.
입력: "ljes=njak"
- "lj"가 "Z"로 대체되어 "Zes=njak"가 된다.
- "nj"가 "Z"로 대체되어 "Zes=Zak"가 된다.
- "=" 뒤에 오는 문자도 포함하여 대체가 일어나지 않기 때문에 결과적으로 문자열은 "Zes=Zak"가 된다.
- 따라서, 문자열의 길이는 6이다.
'코딩 > 백준' 카테고리의 다른 글
| [백준/BOJ] 2738번: 행렬 덧셈 (Python 파이썬) (0) | 2024.06.19 |
|---|---|
| [백준/BOJ] 1316번: 그룹 단어 체커 (Python 파이썬) (0) | 2024.06.07 |
| [백준/BOJ] 1157번: 단어 공 (Python 파이썬) (0) | 2024.06.05 |
| [백준/BOJ] 10988번: 팰린드롬인지 확인하기 (Python 파이썬) (0) | 2024.06.05 |
| [백준/BOJ] 2444번: 별 찍기 - 7 (Python 파이썬) (0) | 2024.06.05 |
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- computation graph
- sorted
- **kwargs
- 경사하강법
- 숏코딩
- 11870
- 백준
- python
- 비용함수
- numpy 배열 생성
- 파이썬
- numpy 배열 속성
- **
- 강화학습
- NumPy
- baekjoon
- 손실함수
- adrew ng 머신러닝 강의
- *
- Andrew Ng
- 딥러닝
- omp: error #15
- 강의노트 정리
- 로지스틱 회귀
- policy function
- state value function
- Sort
- action value function
- 앤드류응
- *args
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
글 보관함