
티스토리 뷰

Numpy 배열(Array) 속성
Numpy 배열은 여러 가지 속성을 가지고 있다.
- ndarray.ndim : 배열의 차원(축)의 개수를 나타낸다
- ndarray.shape : 배열의 모양을 나타내는 정수의 튜플이다. 각 차원에서 배열의 크기를 나타낸다 (정말 많은 곳에서 사용된다. 특히, 딥러닝 분야에서 자주 사용되는 DataFrame형, Tensor형에 자주 쓰이니 중요하다)
- ndarray.size : 배열의 모든 원소의 개수를 나타낸다
- ndarray.dtype : 배열에 저장된 원소의 타입을 나타내는 객체이다. (unit8~unit64, int8~int64, float16~float128, bool 등)
- ndarray.itemsize : 배열에 저장된 각 원소의 크기를 바이트 단위로 나타낸다.
- ndarray.T : 배열의 전치 행렬을 반환한다. T: transpose
아래는 Numpy를 이용하여 배열을 생성하고, 해당 배열에 대한 속성을 출력하는 코드이다. 속성을 출력하면, 차원은 3, 모양은 (2,2,3), 크기는 12, 데이터 타입은 int32, 원소 크기는 4의 값을 출력한다.
import numpy as np
ex_arr = np.array([[[1, 2, 3], [3, 4, 5]],
[[10, 20, 30], [30, 40, 50]]])
print("차원 : ", ex_arr.ndim)
print("모양 : ", ex_arr.shape)
print("크기 : ", ex_arr.size)
print("데이터 타입 : ", ex_arr.dtype)
print('각 원소의 크기:', ex_arr.itemsize)
print('전치 행렬:', ex_arr.T)
#출력 결과
# 차원 : 3
# 모양 : (2, 2, 3)
# 크기 : 12
# 데이터 타입 : int32
# 각 원소의 크기: 4
# 전치 행렬: [[[ 1 10]
# [ 3 30]]
#
# [[ 2 20]
# [ 4 40]]
#
# [[ 3 30]
# [ 5 50]]]
Numpy 배열(Array) 생성
1) Array 함수를 이용한 방법
가장 건던헌 벙봅운 numpy.array() 함수를 사용하여 입력 데이터(리스트, 튜플, 다른 배열 등)를 ndarray로 변환하는 것이다.
# 1차원 배열 생성
a = np.array([1,2,3])
# 2차원 배열 생성
b = np.array([[1,2,3],[4,5,6]])
# 3차원 배열 생성
c = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])2) 다른 함수를 이용한 방법 (arange, linspace, ones 등)
<arrange 함수를 이용한 배열 생성>
Numpy의 arange함수는 특정 구간 안에서 일정 간격의 값으로 구성된 배열을 생성한다.
start 값에서 시작하여 stop 값까지 step 간격으로 수를 생성한다. range함수와 마찬가지로, stop 값은 범위에 포함되지 않는다.
다음 코드는 간격이 2인 0부터 10까지의 값들의 순차열을 생성하는 예제이다.
print(np.arange(0,10,2)) # [0 2 4 6 8]

그런데, range함수와는 다르게 실수 범위도 생성 가능하다.
print(np.arange(0.1,1.1,0.2)) # [0.1 0.3 0.5 0.7 0.9]
물론, 아래 코드와 같이 사용가능하다. 기본적으로 start 값은 0, step은 1이다.
print(np.arange(10)) # [0 1 2 3 4 5 6 7 8 9]<linspace 함수를 이용한 배열 생성>
Numpy의 linspace 함수는 수의 범위를 균일하게 나누고자 할 때 사용한다.
즉, start 값과 stop 값 사이에 균등하게 나누어진 num 개의 값을 생성한다. 여기서, linspace은 끝(stop)을 포함을 시킨다.
다음은 1과 10 사이에 균등하게 나누어진 4개의 값을 출력하는 예제이다.
print(np.linspace(1,10,4)) # [ 1. 4. 7. 10.]

+ 참고
np.arange 와 np.linespace의 차이점
값들의 순차열을 생성할 때, 두 함수는 자주 사용된다.
그러나, 미묘한 차이가 있다.
arange는 단계의 크기를 지정할 수 있고,
linespace는 단계의 개수를 지정할 수 있다.
<기타 함수를 이용한 배열 생성 (ones, full, zeros, eye)>
- np.ones((x, y)) : x by y 사이즈의 1(ones)로 채워진 행렬을 생성한다.
- np.zeros((x, y)) : x by y 사이즈의 0(zeros)으로 채워진 행렬을 생성한다.
- np.full((x, y), n) : x by y 사이즈의 n값으로 채워진 행렬을 생성한다.
- np.eye(x) : x by x 사이즈의 단위 행렬 (identity matrix)을 생성한다.
- np.empty((x,y)) : x by y 사이즈의 초기화되지 않은 배열을 생성한다.
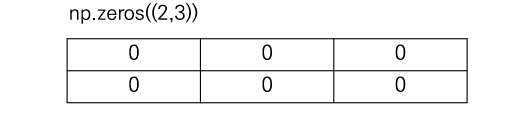
다음은 np.ones((x,y))의 예제이다. 모든 원소가 1인 배열을 생성한다. 연산에서 모든 원소가 1인 배열이 필요할 때 주로 사용된다. 이 함수의 데이터 타입은 float64로 설정되어 있다.
ones_arr = np.ones((2,3))
# 출력 결과
# [[1. 1. 1.]
# [1. 1. 1.]]
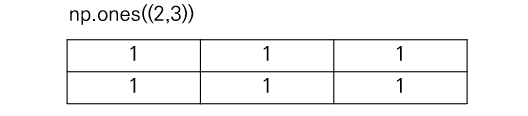
다음은 np.zeros((x,y))의 예제이다. 모든 원소가 0인 배열을 생성한다. 주로 모델의 초기화나 임시 데이터 생성 등에 유용하게 사용된다. 이 함수의 데이터 타입은 float64로 설정되어 있다.
zeros_arr = np.zeros((2,3))
# 출력 결과
# [[0. 0. 0.]
# [0. 0. 0.]]
다음은 np.full((x,y),n)의 예제이다. 모든 원소가 특정 값 n으로 채워진 배열을 생성한다.
full_arr = np.full((2,3),5)
# 출력 결과
# [[5 5 5]
# [5 5 5]]

다음은 np.eye(x)의 예제이다. 주어진 크기의 단위 행렬(identity matrix)을 생성한다. 선형대수학에서 특히 중요하다. 역행렬, 선형 방정식의 해를 구할 때 사용되기 때문이다.
eye_arr = np.eye(3)
# 출력 결과
# [[1. 0. 0.]
# [0. 1. 0.]
# [0. 0. 1.]]

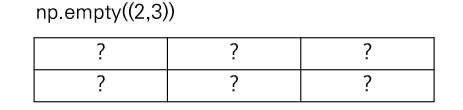
다음은 np.empty((x,y))의 예제이다. 초기화되지 않은 원소로 구성된 배열을 생성한다. 해당 함수를 통해 만들어지는 배열의 초기값은 메모리 상태에 따라 결정되므로, 어떤 값이 들어있는 지 알 수 없다. 보통 무작위 값이 들어가게 된다. 즉, 코드를 돌리 때마다 할당되는 값들이 달라진다. 그리고 해당 함수의 데이터 타입은 float64이다. 배열만 생성하고 초기화하지 않으므로 np.zeros, np.ones 보다 빠르게 실행될 수 있다.
empty_arr = np.empty((2,3))
# 출력 결과
# [[1.50201822e-307 4.67296746e-307 1.69121096e-306]
# [1.33512376e-306 7.56587585e-307 1.37961302e-306]]
'파이썬' 카테고리의 다른 글
- Total
- Today
- Yesterday
- *
- Sort
- baekjoon
- numpy 배열 속성
- 비용함수
- 경사하강법
- 손실함수
- 강화학습
- *args
- computation graph
- policy function
- 강의노트 정리
- 숏코딩
- state value function
- NumPy
- action value function
- Andrew Ng
- 앤드류응
- adrew ng 머신러닝 강의
- **
- numpy 배열 생성
- 11870
- **kwargs
- 로지스틱 회귀
- python
- 딥러닝
- omp: error #15
- 백준
- 파이썬
- sorted
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |